
AnalyticDB PostgreSQL(ADBPG)就是一堆并行的PostgreSQL?当然不是!
ADBPG作为一个基于PostgreSQL的Massively Parallel Processing(MPP)全并行架构的分析型数据库,针对数据分析场景在很多方面得到了加强。如双优化器(GPORCA & PGO)、Platform Extension Framework (PXF)、基于多种存储的分区、资源控制、多压缩算法等等。
在ADBPG数据库中,默认的ORCA优化器与传统查询优化器共存,ORCA对传统优化器(PGO)的优化能力进行了扩展,在数据分析场景下能给出更好的优化。
但是有些场景下会发现传统优化器效果会好一些,所以在很多项目上客户会有这样的疑问:“这两个优化器有什么区别,我应该用哪个?”,当被问到这个问题时,我最初只能默默的回答:“都试试,哪个快用哪个”,很明显这个回答太low了,实在是很不专业。
所以我做了一些学习,本文将会就优化器(ORCA)这个话题分享一些基础知识,作为ADBPG优化基础这个系列的第一章,以下很多内容都是基于我在阅读整理文献后的个人理解,如果有不准确的地方,希望大家能够见谅并帮忙指出,十分感谢。
在ADBPG数据库中,ORCA与传统查询优化器共存。默认情况下,ADBPG数据库会使用ORCA,如果无法使用ORCA(回退),则会使用传统优化器。
下图展示了ORCA如何融合到查询规划架构中的:
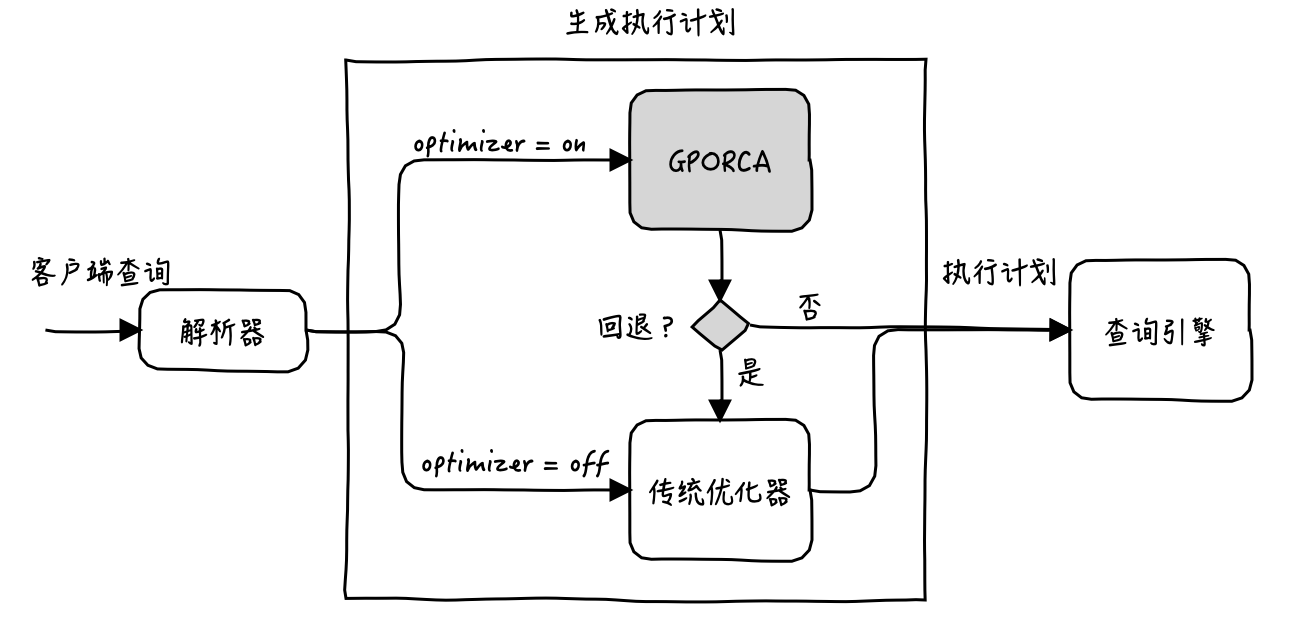
ORCA不同于其他数据库产品的优化器,它是一个相对独立的组件,可以独立运行于数据库系统之外,与数据库不紧密耦合。这个特点让ORCA可以同时支持多种架构的数据库,这里就不展开说了。
既然ORCA独立于数据库系统之外,那么就需要一种新的通信机制来保证ORCA与数据库系统的信息交互,那就是Data eXchange Language(DXL),这是ORCA唯一的交互语言,用DXL装载的信息主要有3类:1)查询语句 Query 2)元数据 Metadata 3)执行计划 Plan
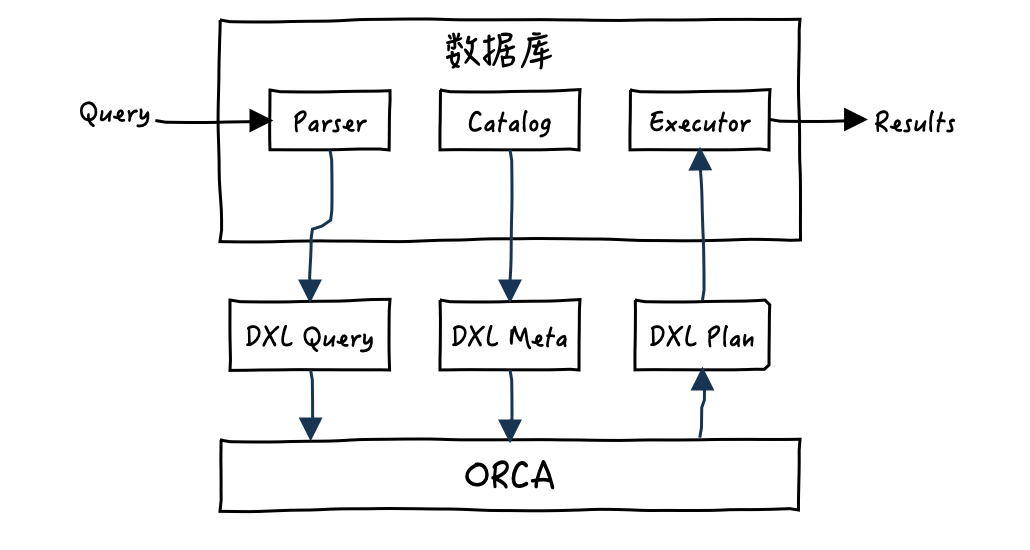
上图是数据库与ORCA优化器的交互过程,当ADBPG接收到一个查询后,会有对应的组件先将其转换为DXL格式,得到了DXL Query后发送给ORCA,ORCA在经过一系列的优化动作(后面会展开介绍)后,会返回一个DXL格式的执行计划(DXL Plan)给数据库,数据库将DXL Plan进行解读后,再继续按照这个计划进行后续的实际物理动作。ORCA在优化的过程中会依赖数据库里的元数据,同样数据库会有对应的组件将元数据转换成DXL meta并发送给ORCA。
下面再来看一下ORCA的内部结构,下图显示了Orca的不同组成部分,我简要的介绍一下这些组件:
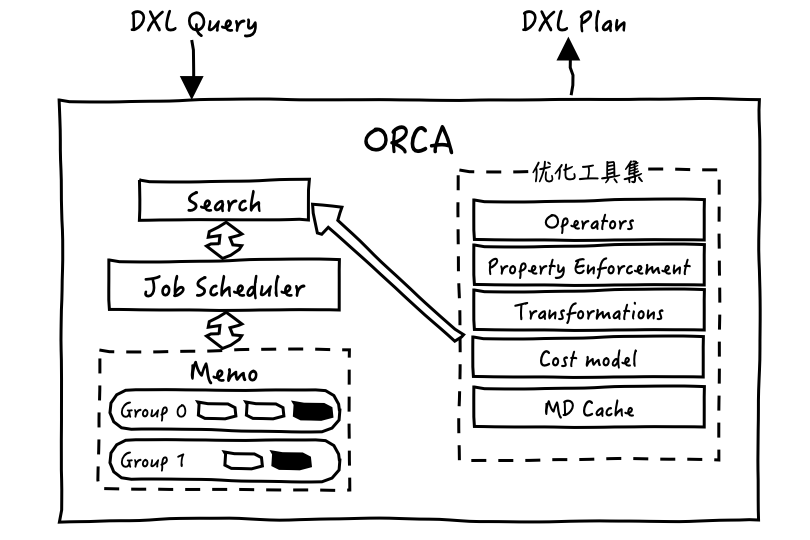
Memo作为一个核心部分,其实就是一块内存空间用来存储所有可能的执行计划,一个Memo中会包含多个group,每个group对应一个当前查询的子目标,子目标可以是查询一张表的数据,或者是对两张表进行关联join等等。每个group中又包含了若干表达式,这些表达式是逻辑等价的,都可以完成所在group对应的查询子目标,只是实现方式不同,如:tableA NL join tableB和tableA hash join tableB的区别。同时group里的表达式可能会依赖其他的group,如:负责做表join的表达式会依赖做表数据扫描的group,听着糊涂没关系,后面会详细介绍。
Search指一种搜索机制,ORCA使用这种机制来遍历Memo中所有可能的执行计划并找到成本最低最好的计划。优化过程主要有三个步骤:
- exploration-探索,用来生成逻辑等价的表达式。
- implementation-实现,用来生成物理执行计划。
- optimization-优化,实现必须的物理属性(例如,排序顺序)并计算各个方案的成本。
Search由专门的Job Scheduler来启用并进行编排调度。
这里我称之为转换规则,优化的前提是我们需要有张“地图”,展示出所有可选的“路”,在ORCA中所有的可选的子计划都是通过应用“转换规则”衍生出来的,转换规则的实现方式主要有两种:
- 生成新的逻辑等价的表达式(如,‘A join B’ 转换为 ‘B join A’,改变了关联顺序)
- 基于表达式,生成具体物理实现方式(如,‘A join B' 转换为 ‘A HashJoin B’)
转换所产生的结果也会添加到Memo中,可以是在现有的group中添加一个新的表达式,也有可能直接创建一个新的group。
这个词我理解了很久,先看下这个词Intellectual Property Enforcement,这个词的意思是“保护知识产权”,对比到我们这里,就是保护产权,产权这里指的是属性,如:排序和数据分布方式,保护指的是确保这些属性能够实现。
属性总共有以下几个类型,包括逻辑属性(如输出列)、物理属性(如排序顺序和数据分布)和标量属性(如连接条件中使用的列)。
在查询优化过程中,表达式可能会要求其子计划具备特定属性,这里我们假设是“排序”。最好的情况是优化过的子计划自身满足排序属性(例如,IndexScan本身就会传递已排序的数据,因为index本身就是排序的),否则就需要在计划中插入额外的表达式(如排序)来满足这个属性要求。
由于元数据(例如,表定义)很少更改,为了避免每个查询都会获取元数据产生开销,ORCA会缓存元数据,并且仅当缓存中没有目标元数据,或者自上次加载到缓存以来发生了更改时,才会从数据库拉取元数据。
好,简要介绍完OCRA的架构和各个组件之后,我们通过一个例子来把这些东西串起来,了解一下SQL是如何一步一步被优化的。
假设我们有以下这样一条简单的SQL语句,这里说明一下,表T1、T2都使用a字段作为分布键。
以下是这条SQL语句转换成DXL后的格式,比较容易理解,有输出列、排序列、数据分布、表关联等信息。
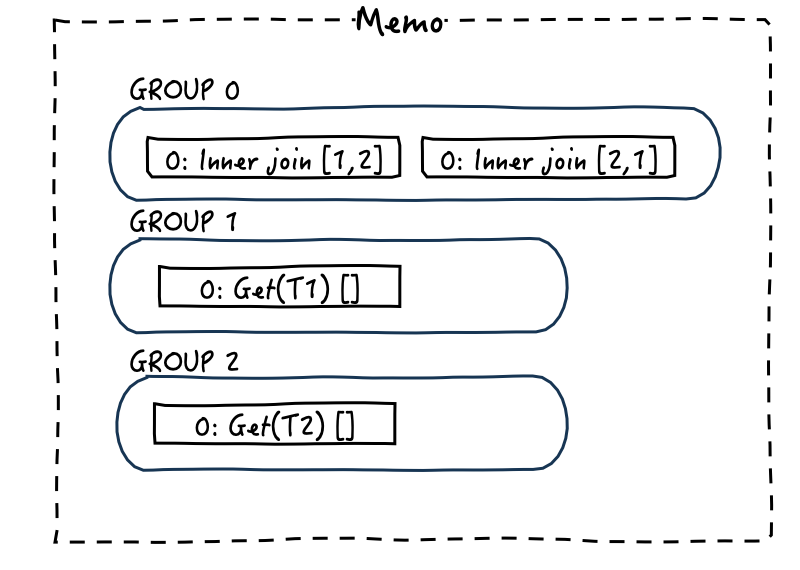
这个DXL query信息被发送到ORCA后,被解析成group表达式,组成了最初的Memo,下图显示了Memo中的初始内容,共有三个group,分别是T1和T2以及这两张表的inner join操作,同时表达式inner join依赖两张表所在的group。
好,现在我们有了初始Memo,接下来就在这个基础上按照后面的几个步骤一步一步的改造这个Memo(优化):
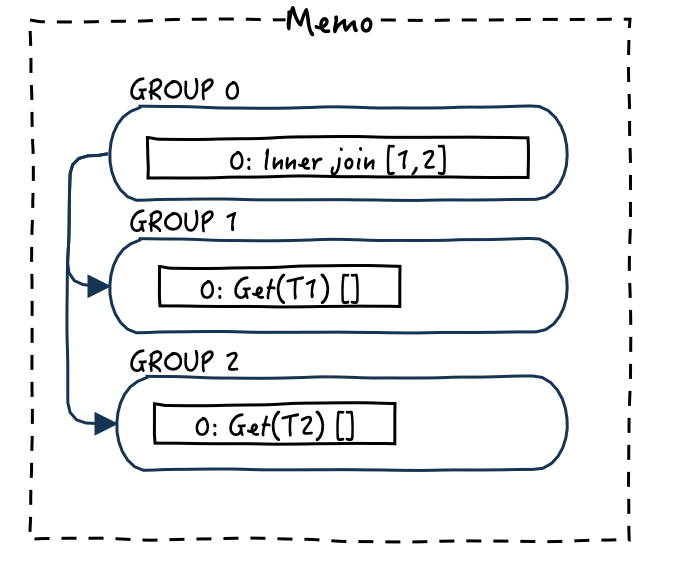
这个阶段需要探索表达式,主要的目标是使用转换规则衍生出新的逻辑等价的表达式。我们以Join Commutativity rule(连接交换规则)为例,基于这个规则,可以将InnerJoin[1,2]衍生出InnerJoin[2,1],通俗点就是T1 join T2衍生了T2 join T1,前后两者连接顺序不同。不同的转换规则有可能会衍生出相同的表达式,但是会有重复检测机制会自动的发现并消除这些重复表达式。
此时的Memo应该是这样:
表达式衍生结束后,ORCA会基于现有的Memo进行统计信息收集,统计的对象主要就是字段直方图的集合,这些元数据会被用于预估某个字段的数据基数或者倾斜度。
首先,在每个group中基于特定的算法选择一个最优的表达式,然后ORCA会递归地对所选group表达式的子group进行统计信息收集。最后,通过组合子group的统计对象来构造目标group的统计信息。
下图是一个统计信息生成的过程。
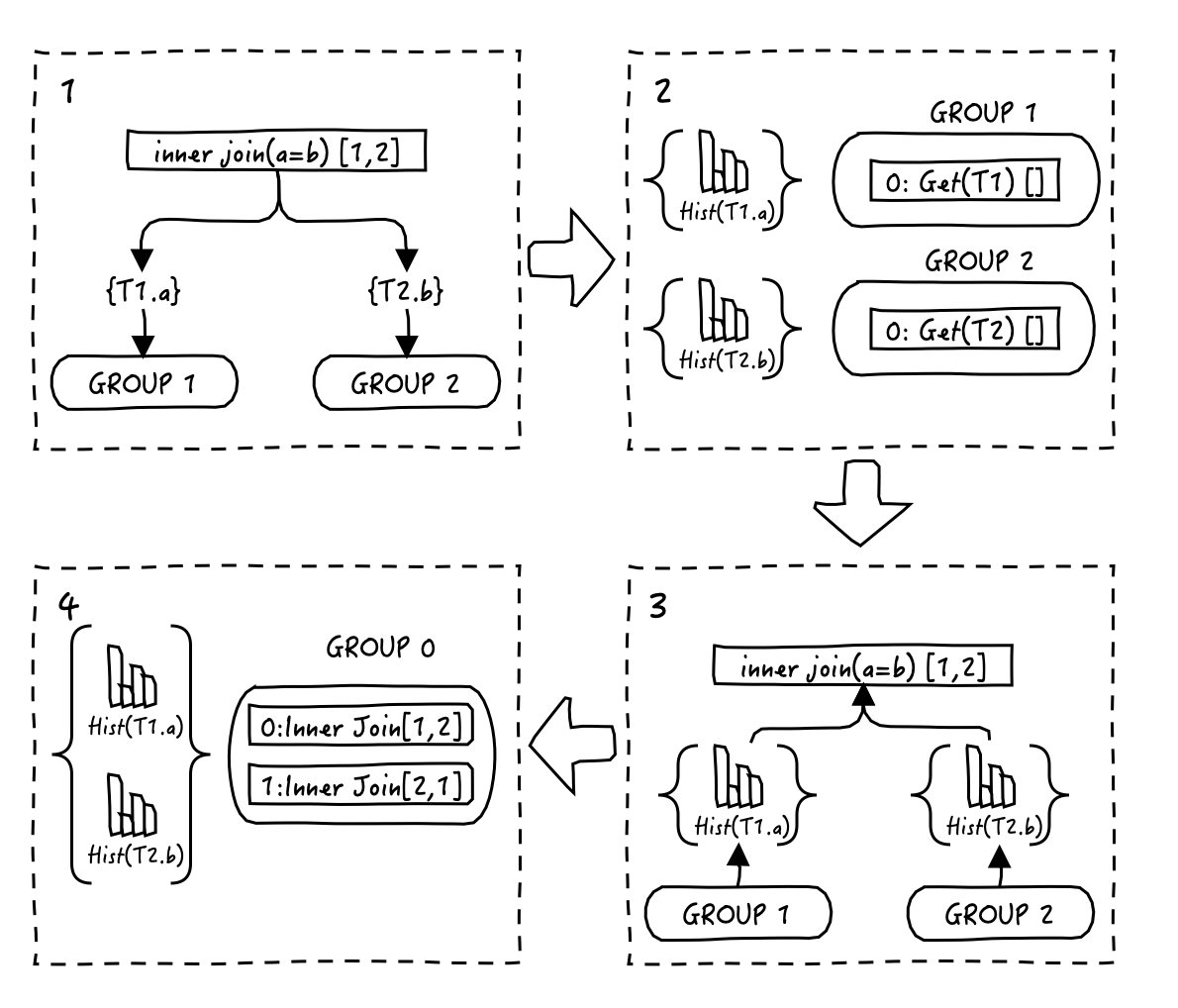
- GROUP 0的表达式从其子group获取统计信息时,首先自上而下的进行。例如,基于a=b的innerJoin(T1,T2) 会请求T1.a的直方图和T2.b的直方图。
- 相关的统计信息数据库会通过DXL Meta发送给ORCA,ORCA接收到后存储在Metadata Cache中,供后续使用。
- 子group收集到统计信息后,自下向上将子统计信息合并到父group的统计信息中去。
- 这样GROUP 0就拥有了T1.a和T2.b的统计信息,为后续选择join计划时(如T1/T2谁作为驱动表更好),提供数据支撑。
此时的Memo应该是这样:

这个阶段跟表达式等价衍生有点类似,但是区别在于这一步是将所有的逻辑表达式转换为物理实现方式,而不再是衍生新的逻辑等价的表达式了。例如,Get2Scan规则会将逻辑get转化为物理table scan,类似的,InnerJoin2HashJoin和InnerJoin2NLJoin规则会将inner join分别转换为hash join和 Nested loop join。
此时的Memo应该是这样:

在得到了全部group的所有可能的物理实现方式后,终于要开始优化了,在此步骤中,首先所有属性会被实现,然后计算所有子计划的成本,最后生成最优执行计划。
优化的开始是一个请求(request),根据我们实际的查询SQL最终是希望得到排序后的T1.a字段的所有值,因此最初的请求是:
#1:{Singleton, <T1.a>}
这个请求格式用逗号分为两部分,第一部分是数据分布,这里的Singleton指的是数据汇集到Master节点,而不是分散在各个Segment节点上;第二部分是排序,这里<T1.a>指的是按照T1表的a字段进行排序;如果任意部分出现Any,则表示对该部分没有要求。
请求确定后,开始基于group中的表达式进行优化,表达式在接收到请求以后,会做两件事,以Group 0中InnerHashJoin[1,2]表达式为例:
- 表达式结合自身与请求的实际情况发送子请求给其他的group,例如:InnerHashJoin[1,2]在接收到#1:{Singleton, <T1.a>}请求后,进而发出子请求有以下几种:
- 扫描T1表
- 扫描T2表
- 根据a字段对T1进行重新分布
- 根据b字段对T2表重新数据分布
- 广播T1表
- 广播T2表。
这些请求会集中记录在一个名叫groups hash table的内存区域里,在这张表中最终还会记录每个请求对应最优表达式。
- 针对所有子请求,ORCA会根据收集的统计信息计算出成本最小子请求,并与InnerHashJoin[1,2]进行关联,同时所有子请求也会关联各自最优的表达式。
- 在找到最优的子请求后,检测其排序和数据分布情况,是否满足父请求,这里明显不满足,缺少数据汇集和排序,因此需要添加相应的表达式到Group 0中,Sort(T1.a)、Gather、GatherMergre(T1.a),Gather作用是汇集所有segment节点上的数据到master节点。GatherMerge是将所有segment节点上的已经排序的数据汇集到master节点,同时保证数据已经是排序的。
这样表达式InnerHashJoin[1,2]完成了所有优化任务,继续其他表达式的优化。最后在所有的表达式完成优化后,我们就得到了最终的Memo。

将表达式和请求按照最优路径关联起来,就得到了这个SQL的最优执行计划。

这部分理解起来对于我来说还是花了不少时间的,如果有不同意见,欢迎指出讨论。
说了这么多,不测试一下性能看不出效果,于是我针对ORCA和传统优化器分别做了一次TPC-H测试,数据量为1TB,32个segment,结果如下:
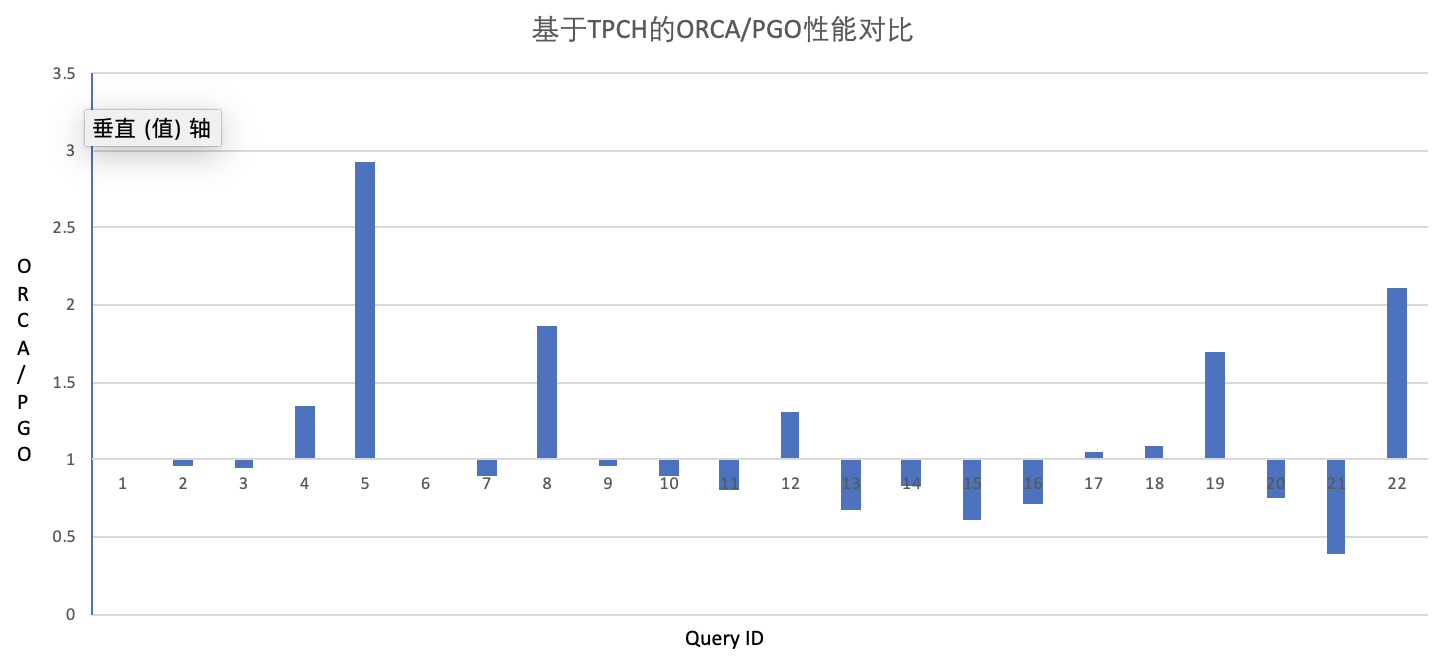
实话实说,总体来说效果不是很明显,两个优化器的表现基本上在一个水平,由于时间和条件限制,没有再做进一步深入的测试。
下面这张图是从《Orca: A modular query optimizer architecture for big data》中截取的,是针对ORCA和传统优化器的TPC-DS测试,数据量为10TB。
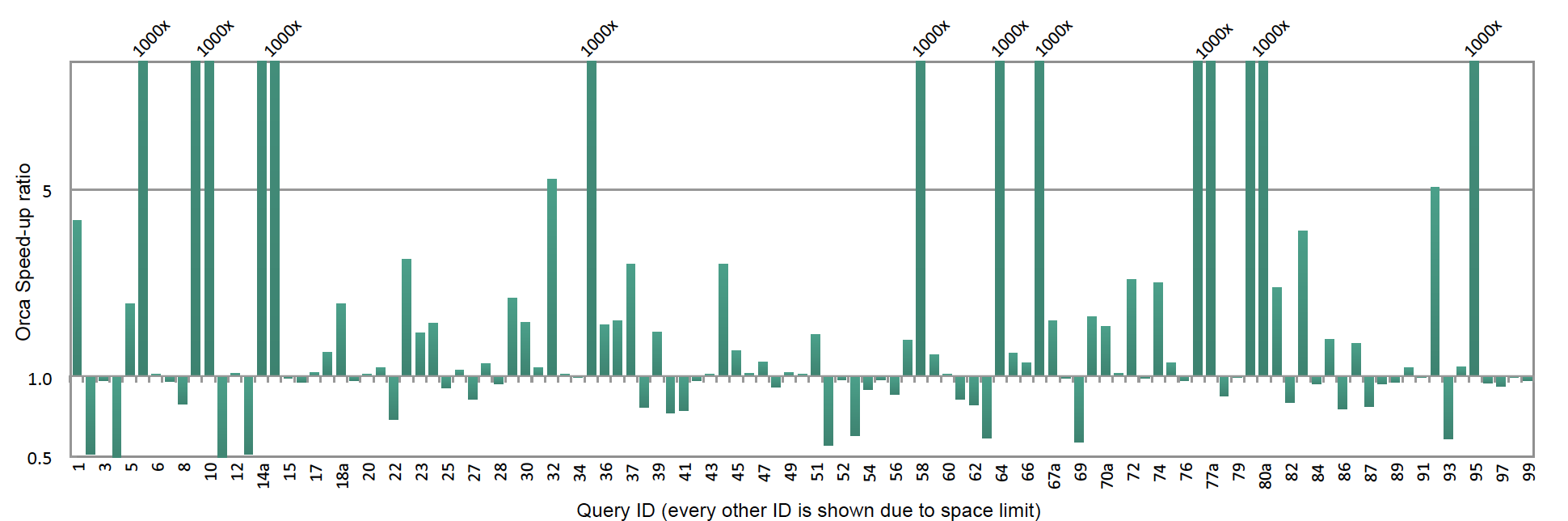
可以看到在更大的数据量和复杂查询的条件下,传统优化器还是能在部分场景下表现的更好,但是这个程度有限的,性能增长不会超过1倍,反观ORCA,在大约15%的场景下性能增长是传统优化器的1000+倍,这个是一个极大的效率提升,很明显权衡利弊,OCRA是一个更好的选择。
下面的内容基本来自于官方文档,做了一下整理,大家也可以直接去官网学习。
如果希望使用ORCA时能达到最佳的效果,需确保满足下列条件:
- 表不含有多列分区键。
- 多级分区表必须是统一多级分区表。
- 对于只存在于Master上的表(例如系统表pg_attribute),在进行运行时,配置参数optimizer_enable_master_only_queries建议设置为on。注意: 启用这一参数会降低catalog短查询性能。为了避免这一问题,建议只对会话或者查询设置这一参数。
- 分区表的根分区上收集了统计信息。
- 如果分区表包含超过20,000个分区,建议重新设计该表分区。
ORCA在生成执行计划时,在以下方面做了增强:
- 对分区表的查询
- 含有子查询的查询
- 含有公共表表达式的查询(WITH AS)
- DML操作增强
- 改进的连接排序
- 连接-聚集重排序
- 排序顺序优化
- 查询优化中包括的数据倾斜估计
相比使用传统规划器,启用ORCA优化器会对数据库的行为有些改变:
- 允许在分布键上的UPDATE操作。
- 允许在分区键上的UPDATE操作。
- 支持对统一分区表的查询。
- 对更改为使用外部表作为叶子分区的分区表的查询将回退到传统优化器。
- 不支持直接在分区表的分区(子表)上的DML操作,INSERT除外。对于INSERT命令,可以指定分区表的一个叶子子表来把数据插入到分区表中。 如果该数据对于指定的叶子子表不合法,则会返回一个错误。不支持指定一个不是叶子的子表。
- 如果命令CREATE TABLE AS中没有指定DISTRIBUTED BY子句且没有指定主键或者唯一键,它将会随机分布表数据。
- 分区表的根表上需要统计信息。ANALYZE命令会在根表和个别分区表(叶子子表)上生成统计信息。
- 查询计划中添加额外的Result节点:Assert算子、Partition selector算子、查询计划的Split算子。
- 在运行EXPLAIN时,ORCA生成的查询计划与传统查询优化器生成的计划不同。
- 当启用了ORCA且数据库回退到传统查询优化器生成查询计划时,数据库会增加日志文件消息Planner produced plan。
- 当一个或者更多个表列的统计信息缺失时,数据库会发出一个警告。 在用ORCA执行SQL命令时,如果该命令的性能可以通过在它引用的列或者列组上收集统计信息而提升,数据库会发出警告。
由于ORCA不支持所有的ADBPG数据库特性,所以这里会介绍ORCA优化器存在的一些限制。
下面这些是ORCA被启用时不支持的特性:
- 具有参数值的prepared statement。
- 索引表达式(使用表的一个或者更多列组合的表达式定义的索引)
- SP-GiST索引方法。ORCA支持B-tree、Bitmap,GiST和GIN索引,忽略使用不支持的方法创建的索引。
- 外部参数
- 以下类型的分区表:1)非统一分区表 2)被修改为用一个外部表作为叶子子分区的分区表。
- SortMergeJoin (SMJ).
- 有序聚集
- 分析扩展:CUBE,多分组集
- 标量操作符:ROW,ROWCOMPARE,FIELDSELECT
- 将集合运算符作为输入参数的聚合函数。
- percentile_*窗口函数(不支持有序集聚合函数)。
- 逆分布函数
- 执行用ON MASTER或 ON ALL SEGMENTS属性定义的函数的查询。
- 在元数据名称(如表名)中包含Unicode字符的查询,以及字符与主机系统区域设置不兼容。
- 表名由关键字ONLY指定的SELECT,UPDATE和DELETE命令。
- 按列排序规则。只有当查询中的所有列都使用时,ORCA才支持排序规则相同的排序规则。如果查询中的列使用不同的排序规则,则使用传统查询计划器。
启用ORCA时,已知下列特性会发生性能衰退:
- 短查询 - 短查询可能会因为ORCA对于判断最优查询执行计划的增强而产生额外的性能衰减。
- ANALYZE - 对于ORCA,ANALYZE命令为分区表生成根分区的统计信息。对于传统优化器,这些统计信息不会被生成。
- DML操作 - 对于ORCA,DML操作在分区和分布键上的更新上进行了增强,这可能会产生额外的负担。
下一章计划分享一些SQL优化技巧相关的内容。
参考文献:
https://gpdb.docs.pivotal.io/6-4/admin_guide/query/topics/query-piv-opt-changed.html

